in this article
As more and more new technologies come on the scene, researchers’ ability to generate and store massive datasets is on the rise. But doing something with that data is a different question.
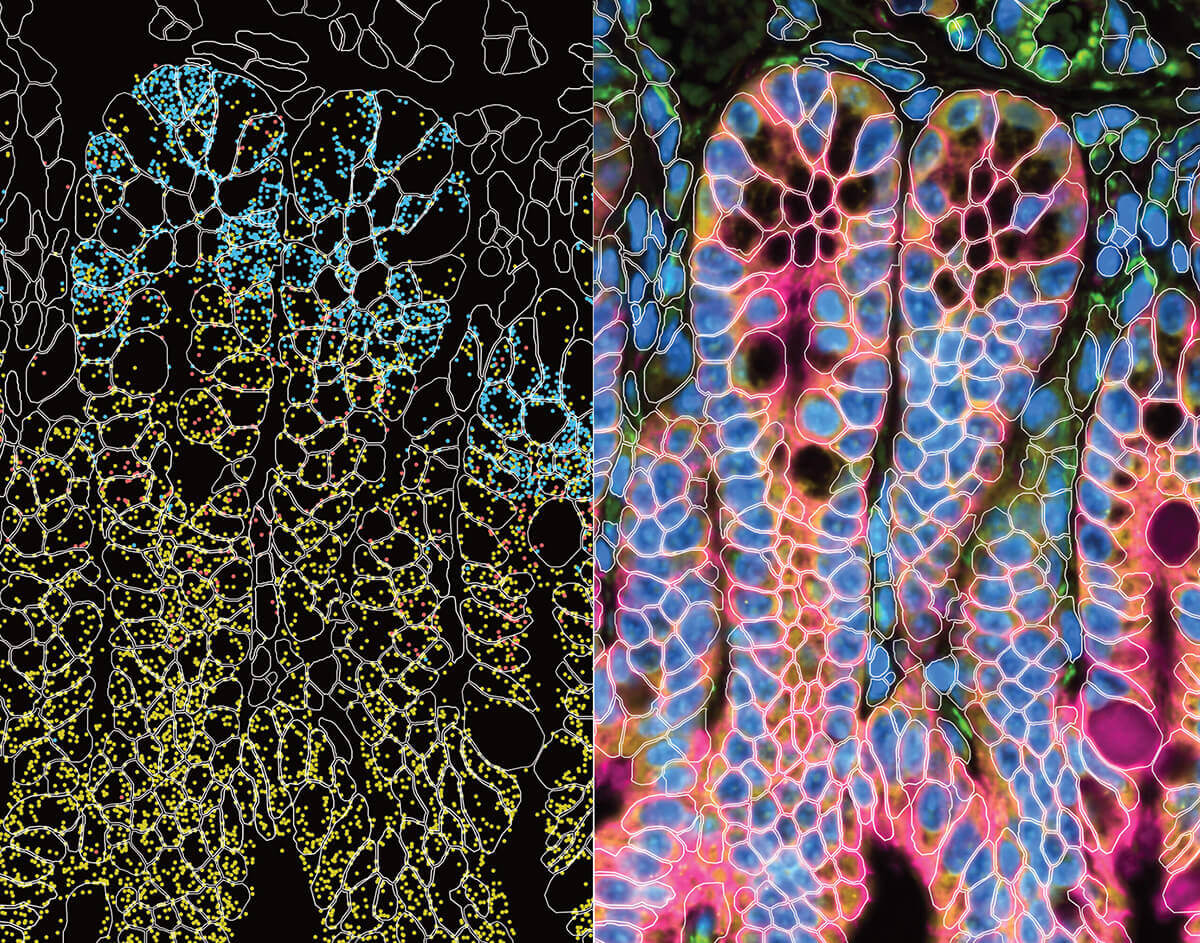
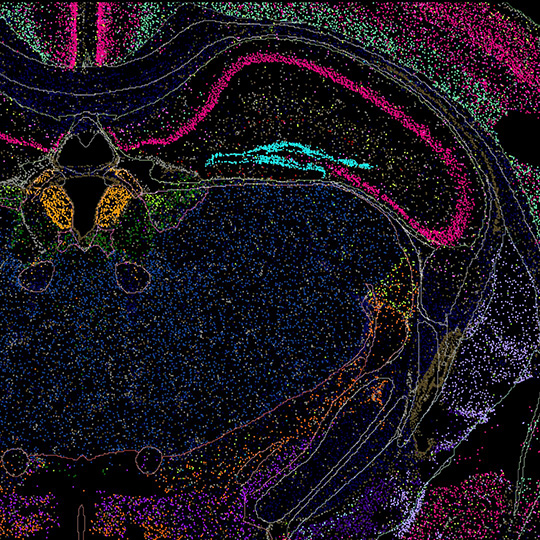
It’s a massive engineering challenge to package, store and present biological data so that other scientists can use it to glean new insights.
Paul Meijer, Ph.D., Director of Software Development at the newly launched Allen Institute for Immunology, is up for that challenge. Beyond the standard “data governance issues” that modern biology presents, the Allen Institute for Immunology has some formidable data challenges of its own. Meijer and his team will need to coordinate anonymized data from hundreds of different patients and healthy volunteers gathered by the Institute’s five different research partner organizations, allowing the partners and the broader scientific community to understand, access — and ultimately analyze — all that data.
We sat down with Meijer, who started out his career as a research psychologist before moving to software development, to find out more about what brought him to the Allen Institute, his vision for his team, and why he’s so excited about the mountains of immunology data that are soon headed his way. The conversation has been lightly edited for length and clarity.
What do you do in your role?
My goal — and my team’s goal — is to develop any and all tools so that the data we generate can be collected, analyzed and shared among our research partners, and with the broader scientific community, and in some ways even with the general public.
You used to be a psychology researcher. What led you to software development?
My background is in experimental and cognitive psychology. I studied speech production patterns in people and using the computer to model human processes was a natural next step. This was around the time when people were starting to do deep learning models and timely computational analysis became a reality for many researchers. It was natural for me to start learning some programming languages to see if we could model the results of our experiments with human subjects. So I had the background in both, and at some point I decided to just make the switch to pure software development.
What brought you to the Allen Institute for Immunology?
It’s definitely satisfying to come into a role that combines software development and research. It’s kind of the best of both worlds. Many other jobs in software limit you to solving problems that are commercially viable. There are very few jobs where you have the opportunity to identify and solve real needs without having to worry first about a licensing model. That’s incredibly liberating.
But it’s also really great to be part of something new. We’re only a few months old now and it’s really exciting to get to step in and build new tools from scratch, many of which we don’t even know yet what they will be.
And being part of a translational institute that will have a clinical impact in people’s lives, that’s very motivating. Of course, we still have to find out if we will be successful – but I think we will be.
What makes the Allen Institute for Immunology unique?
I will first start with the caveat that I’m by no means an immunology expert, so my perspective is maybe more in line with that of the general public, with a bit of a research background. But I think the longitudinal aspect (following patients over long periods of time) is very interesting. That’s not commonly done in immunology, as those studies are difficult and costly.
From a technology perspective, scientific organizations everywhere are grappling with an effective data governance model and it’s only getting worse as data sets become larger and larger. Too often articles are published and datasets are made publicly available with minimal guidance on how to work with this data, making it next to impossible for other scientists to pick up that data and understand how to analyze and verify it. This problem is not unique to immunology, but our field produces a huge amount of data. As a scientific discipline we could do a lot better. That’s a technological problem that I’m really interested in working on.
What’s your vision for your team? Where do you see yourselves two years down the road?
In terms of development, our main focus will be on making sure that everyone in the Institute here and our research partners are able to easily share data, and that any pipelines to analyze these data are in place. We will also be focused on developing a lot of visualization tools for our scientists to explore the data.
Beyond just the products, I would also love to help bring some visibility into the great engineering happening across the Allen Institute, not just in the immunology group. I have been very impressed with some of the cool scientific computing tools built at collaborating organizations right here in South Lake Union in Seattle and across the world, and we should similarly highlight and share what we have built to the greater community. I think the tools the engineers at the Allen Institute build could be useful to a lot of different audiences, and not just in our direct scientific areas.
Citations
about the allen institute
Allen Institute is a 501(c)(3) nonprofit medical research organization dedicated to accelerating science for a healthier world. Through large-scale, multidisciplinary research initiatives, the Institute generates foundational knowledge, data, tools, and models that are shared openly with the world to advance our understanding of life and health. Founded by Jody Allen and the late Paul G. Allen, Allen Institute is supported primarily by the Fund for Science and Technology.

.avif)