discover/
immunology
immunology
Creating the ultimate reference for the healthy human immune system to help scientists pinpoint what changes in disease.

Your immune system is unlike anyone else's. That's what makes understanding it so hard—and so important.
Every immune system is unique, shaped by age, genetics, and a lifetime of experience. Researchers studying autoimmune disease, cancer, or infection need to understand what normal looks like in order to make sense of what's changed, but that baseline has been frustratingly out of reach.
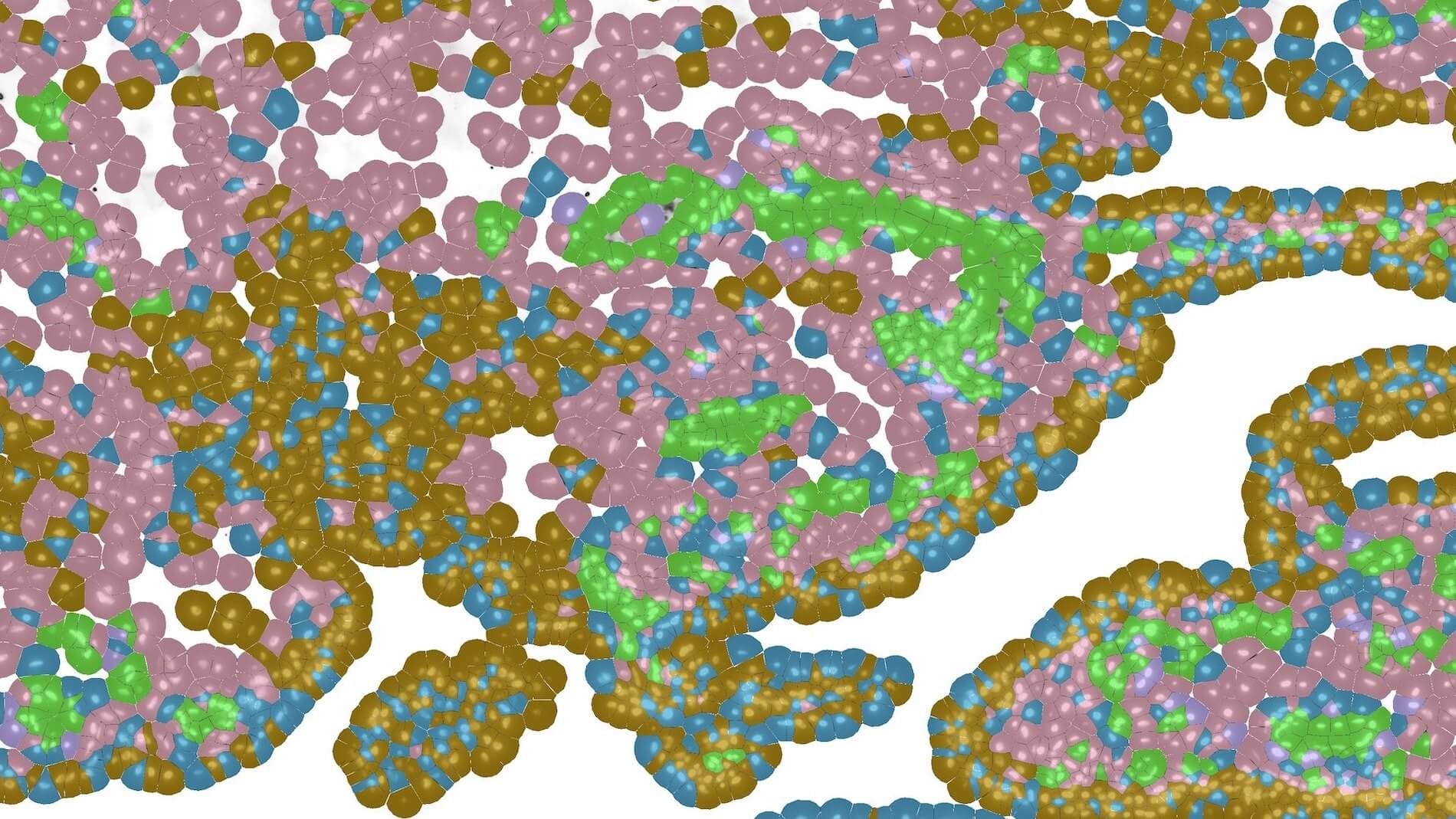
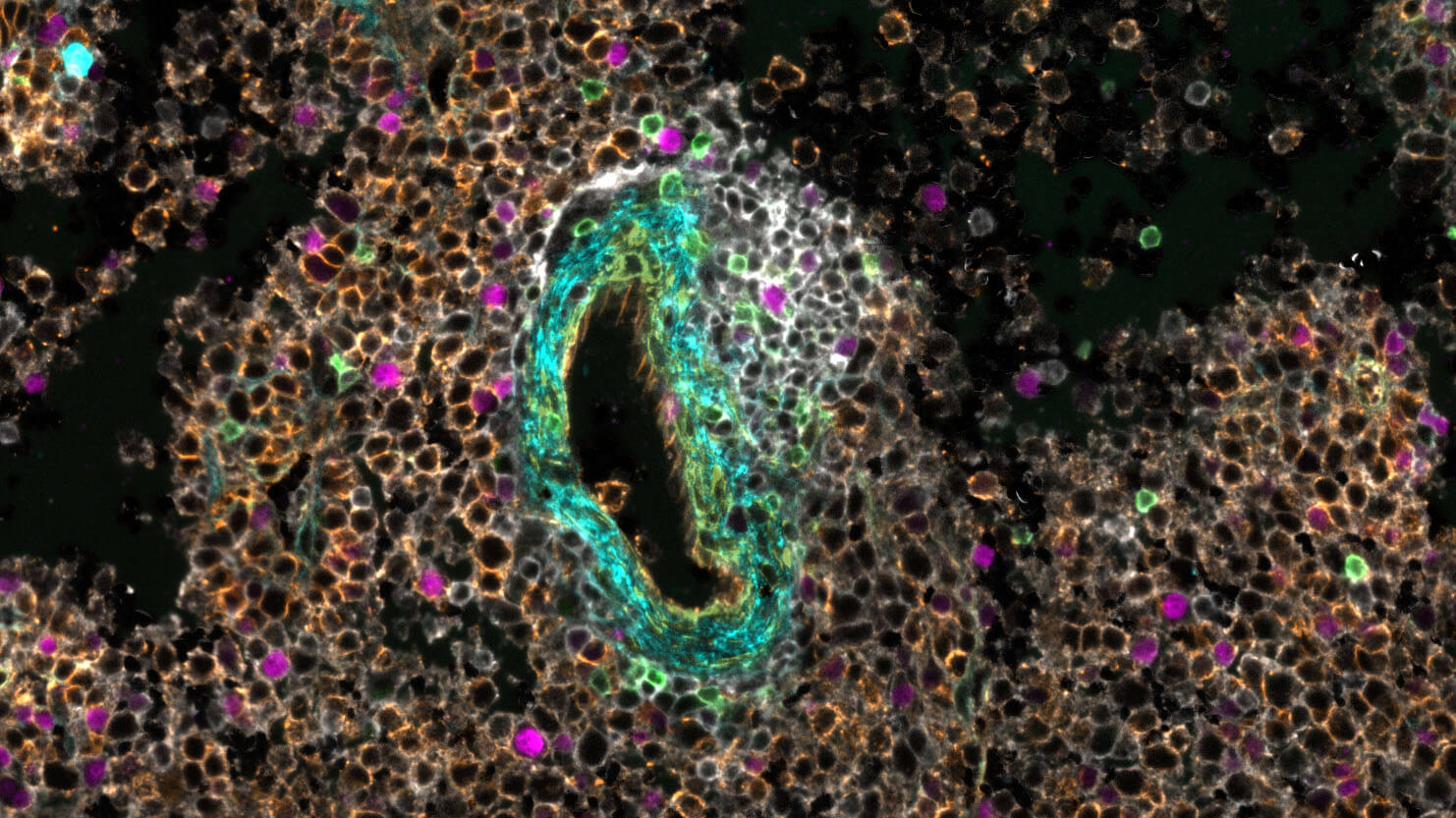
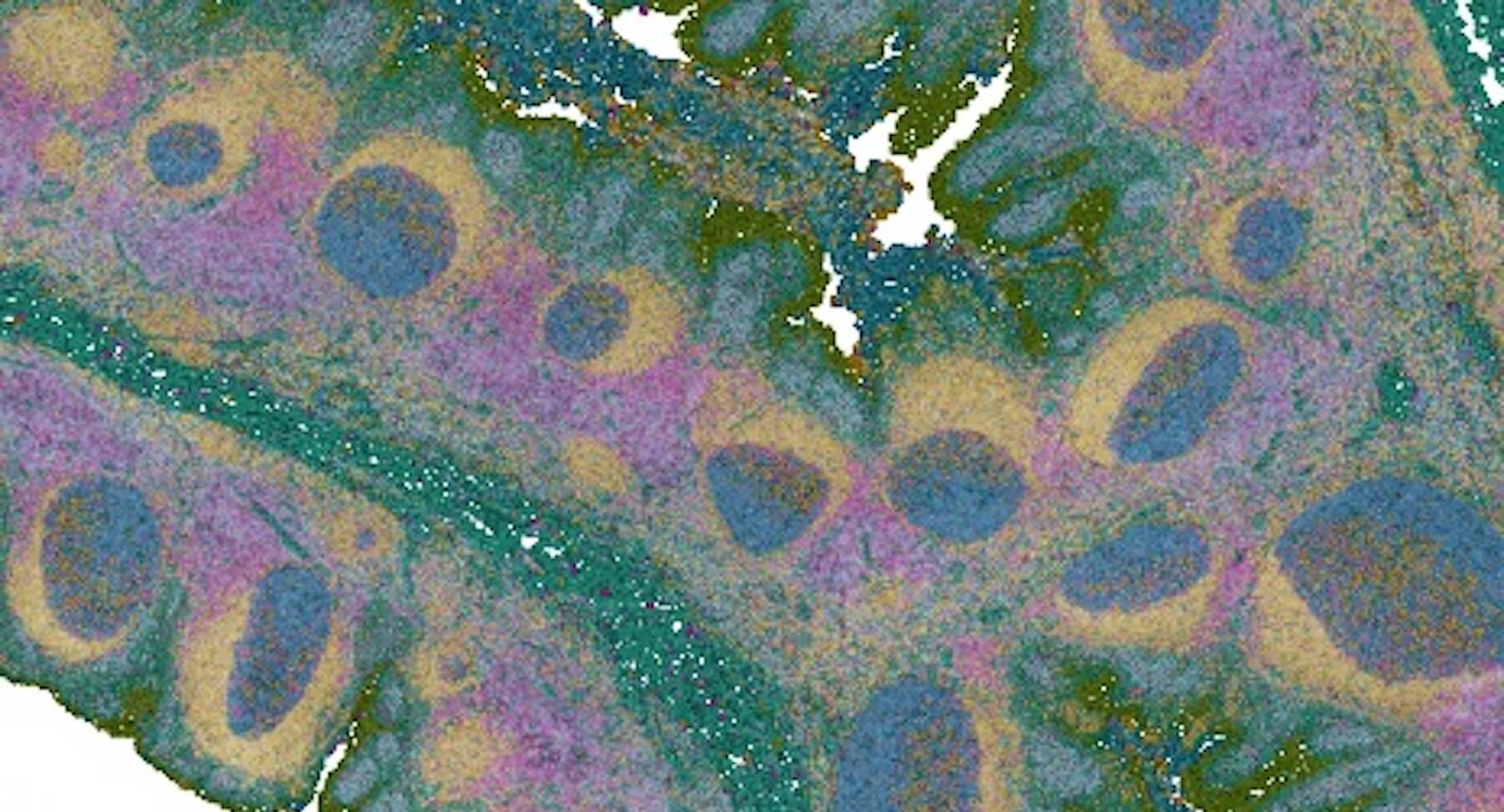
Our Immunology program combined years of longitudinal data, multiple data types, and profiles from hundreds of participants to build a rich, open reference for the healthy human immune system across the lifespan. In the process, we discovered that some diseases are molecularly active years before a diagnosis is possible: a finding that could change how medicine approaches prevention.
A comprehensive baseline for the healthy immune system—free and open to all—gives disease researchers the context they need to understand exactly what's going wrong.
.jpg)
immunology news

.avif)


The immune system is one of the most powerful forces in human biology. By studying human immune responses to infection, vaccination, and autoimmunity—and how immune cells communicate with the nervous system—we aim to harness immunity to prevent disease and end human suffering.
Susan Kaech
Executive Vice President and Director, Immunology
Block Quote
This is some text inside of a div block.
This is some text inside of a div block.
featured publications
Provide proactive reproducible analysis transparency with every publication
Royal Society Open Science
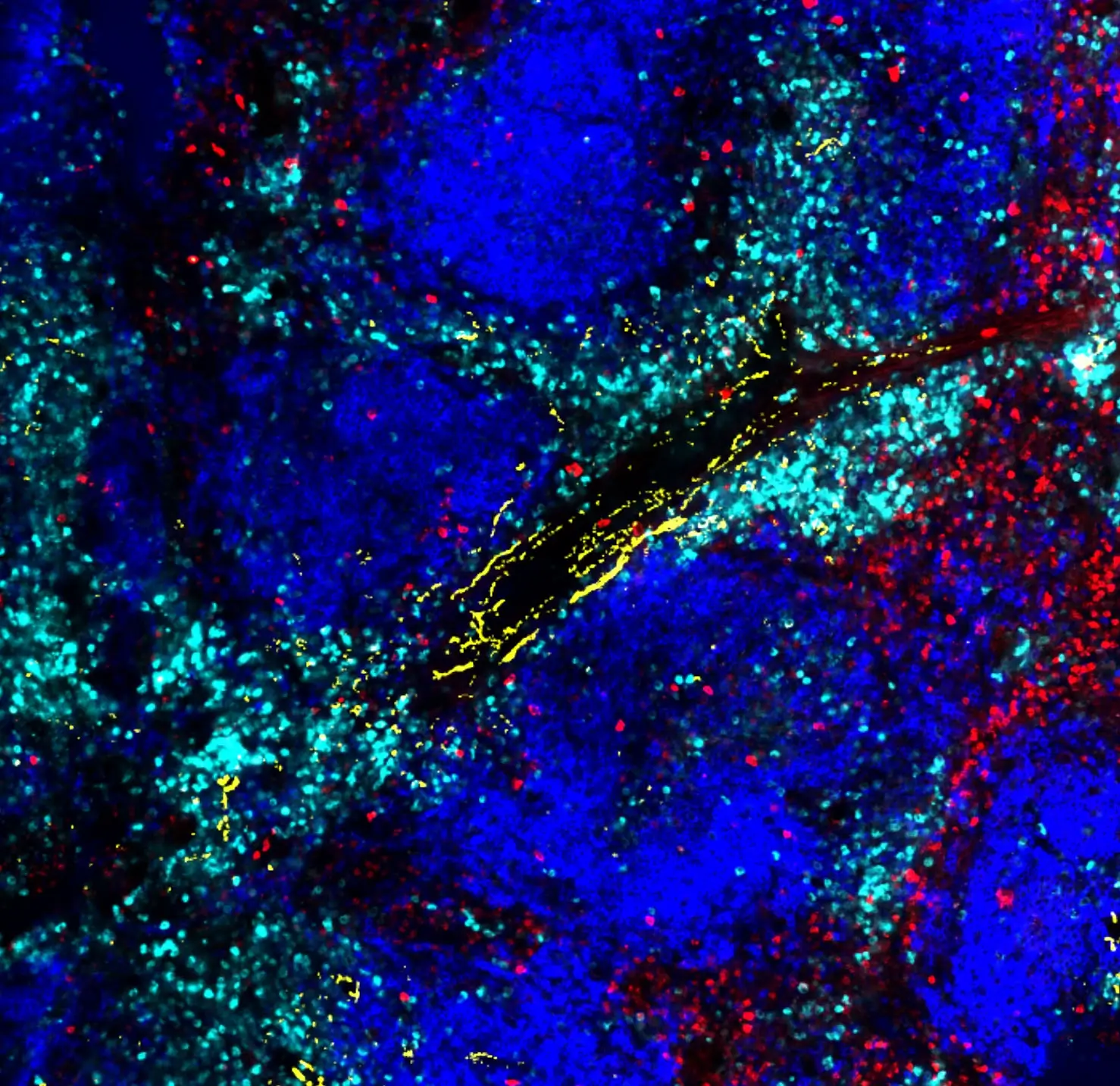
Tissue-resident memory CD8 T cell diversity is spatiotemporally imprinted
Nature
CryoSCAPE: Scalable immune profiling using cryopreserved whole blood for multi-omic single cell and functional assays
Journal of Translational Medicine

access open tools, resources, datasets, and more
immunology events

immunology scientific advisory council







